One issue I had with the new setup that was frustrating me was that, when docked, the laptop would keep a strong preference for wireless connections over wired ones. Apparently, Windows 7 defaults to using some customized route preference calculation metric, and had my wireless at 90 and my wired connection at 900-ish. (Lower scores indicate stronger affinity.)
You can see your current, auto-assigned routing metrics by typing netstat -r from a command prompt, and looking in the 'Metric' column of hte IPv4 Route Table.
When I'm docked, I want wired to take precedent, as the wired connection has a static IP, and makes certain dev and admin tasks possible that cant' be done around here on a regularly-shifting DHCP address on wireless - things like sending SMTP mails without credentials, the way servers get to.
So, using an articles from Lifehacker and Palehorse as a starting point, I set forth to change my interface metrics to suit my needs.
- Starting with Control Panel\Network and Internet\Network and Sharing Center, click the wired connection under Connections:
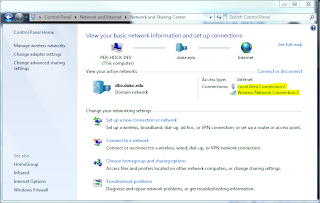
- Then click 'Properties'.
- Then select 'Internet Protocol Version 4 (TCP/IPv4)' and click 'Properties'.
- Click 'Advanced' at the bottom of the window.
- Un-check the 'Automatic Metric' box, and enter a new routing metric here. Lower numbers are higher priority. I used a routing metric of 10 for my wired connection and 200 for my wireless, and everything seems to be behaving exactly as I want.

- Repeat from #1 selecting your wireless network connection.
- Reboot when done to have the new assignments take effect.


As above, you can verify your assignments by typing netstat -r from a command prompt, and looking in the 'Metric' column of hte IPv4 Route Table.
A word of warning: you may want to check with your networking people before you do this. Routers can assign this metric, and overriding what they assign may have unintended consequences for how you access your networks.
Bill